
블로그로 수익을 내보려다 첫 벽에 부딪혔다. 문제는 글 쓰는 실력이 아니라 반복노동의 총량이었다. 키워드를 고르고, 검색 의도에 맞게 글을 쓰고, 이미지를 만들고, 플랫폼마다 형식을 바꾸는 일. 한 편은 손으로 되지만 매일은 못 버틴다. 그래서 이 과정을 Claude Code 위에서 스킬 파이프라인으로 묶었다. 이 글은 그 설계와, 만들면서 실제로 막혔던 지점들을 정리한 기록이다.
목표부터 정했다: 완전 무인이 아니라 “반자동”
처음부터 완전 자동화는 목표가 아니었다. 이유는 두 가지다. 첫째, AI가 쓴 글을 검수 없이 발행하면 품질 사고가 난다. 둘째, 완전 무인은 만드는 비용이 훨씬 크다. 그래서 경계를 이렇게 그었다.
사람은 “키워드 수락”과 “검수·발행”만. 그 사이의 반복은 전부 자동.
이 한 문장이 이후 모든 설계 결정의 기준이 됐다.
전체 구조: 마스터 글 1개 → 플랫폼 출력 N개
핵심 구조는 단순하다. 파이프라인은 하나의 마스터 글을 만들고, 플랫폼마다 다른 출력으로 파생시킨다. 워드프레스는 마크다운을 그대로 받으니 마스터가 곧 발행본이고, 네이버는 마크다운을 못 받으니 별도 변환을 거친다.
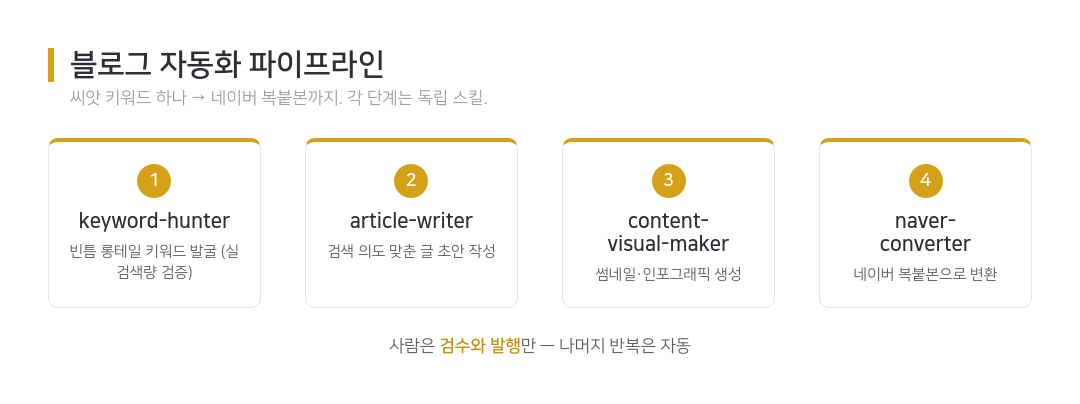
스킬 4개로 쪼갠 이유
글 한 편이 나오기까지를 네 개의 독립 스킬로 나눴다.
| 스킬 | 입력 | 출력 |
|---|---|---|
| keyword-hunter | 씨앗 분야 1개 | 빈틈 롱테일 키워드 랭킹 |
| article-writer | 키워드 1개 | 발행용 글 |
| content-visual-maker | 글 | 썸네일·인포그래픽 |
| naver-converter | 글 | 네이버 복붙본 |
한 덩어리 프롬프트로 만들지 않고 굳이 쪼갠 이유는 유지보수와 합성 때문이다. 글은 잘 나오는데 키워드 선정이 약하면, keyword-hunter만 고치면 된다. 각 스킬은 입력과 출력이 명확해서, 하나를 교체해도 나머지는 그대로 재사용된다. 파이프라인은 코드가 아니라 이 스킬들의 조합일 뿐이다.
시행착오 1 — 감으로 고른 키워드는 대부분 틀렸다
초기 keyword-hunter는 검색량을 정성적으로 추정했다. web_search 결과와 자동완성을 보고 “이 정도면 수요 있겠다”고 판단하는 식이다. 결과 테이블은 그럴듯해 보였다. 문제는 실측을 붙이자 드러났다. 네이버 검색광고 API로 실제 월간 검색량을 조회해보니 이랬다.
| 키워드 | 감(추정) | 실측 월 검색량 |
|---|---|---|
| 제습기 물 안참 | 유망 ★★★ | 약 30회 |
| 서큘레이터 방향 | 보통 | 10~100회 |
| 에어컨 실외기 청소 | — | 6,170회 |
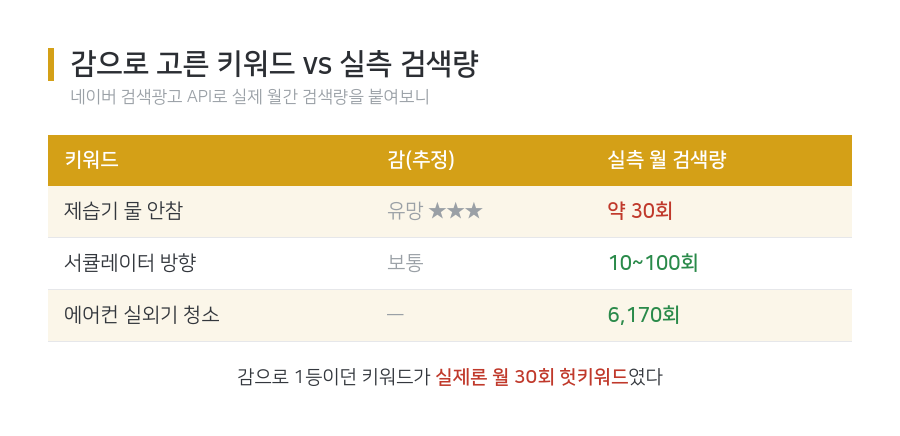
“제습기 물 안참”은 감으로는 최상위였는데 실제로는 월 30회짜리 헛키워드였다. 이런 키워드로 글을 쓰면 아무도 안 읽는다. 결국 후보 롱테일을 생성한 뒤 그 후보들의 실검색량을 API로 검증한 뒤 랭킹하도록 바꿨다.
네이버 검색광고 API는 무료이고, 요청에 HMAC-SHA256 서명이 필요하다.
msg = f"{timestamp}.GET.{uri}"
signature = base64.b64encode(
hmac.new(secret.encode(), msg.encode(), hashlib.sha256).digest()
).decode()교훈은 분명하다. 자동화의 판단 기준은 감이 아니라 데이터여야 한다. 감은 그럴듯할수록 위험하다. 함정도 하나 배웠다. API가 주는 “경쟁도(compIdx)”는 광고 입찰 경쟁이지 블로그 SEO 경쟁이 아니다. 광고 경쟁이 높다는 건 오히려 수익성(CPC)이 높다는 신호다.
시행착오 2 — 이미지는 “있는 도구”로 해결됐다
이미지를 만들 때 처음엔 브라우저 자동화(Playwright)로 화면을 캡처하려 했다. 그런데 작업 환경에 크롬이 설치돼 있지 않아 막혔다. 크롬을 새로 설치할 수도 있었지만, 그 전에 환경을 뒤져보니 wkhtmltoimage가 이미 깔려 있었다.
wkhtmltoimage --width 1200 --height 630 \
--load-error-handling ignore thumb.html out.png이 방식의 장점이 하나 더 있었다. 코드로 그린 이미지는 원본이라, 네이버의 AI 이미지 감지와 무관하다. 작은 함정도 있었다. 시스템에 컬러 이모지 폰트가 없어서 이미지 안의 이모지가 렌더되지 않았다. 결국 이모지 대신 텍스트와 도형으로 강조하도록 바꿨다. 거창한 방법을 찾기 전에 환경에 뭐가 있는지부터 보는 편이 빠르다.
시행착오 3 — 무엇을 자동화하지 “않을지”도 설계다
네이버는 공식 발행 API가 없다. 그래서 브라우저 자동화로 올릴 수도 있었다. 하지만 이건 약관상 회색지대이고, 계정 정지 리스크를 감수할 만큼의 이득은 없다고 판단해 자동 발행을 일부러 뺐다. 대신 사람이 복붙하기 좋은 형태까지만 만든다. 무엇을 자동화하고 무엇을 사람에게 남길지, 그 경계를 정하는 것도 파이프라인 설계의 일부다.
아직 부족한 것 (솔직하게)
- 네이버에 붙여넣은 뒤 소제목을 굵게 하는 건 아직 수작업이다.
- 본문 표를 이미지로 바꾸는 건 지금은 HTML 템플릿을 손으로 만든다.
- 구조화 데이터(FAQ·Article JSON-LD 스키마)를 아직 안 넣었다.
- 완전 무인이 아니다. 그리고 그건 의도된 것이다.
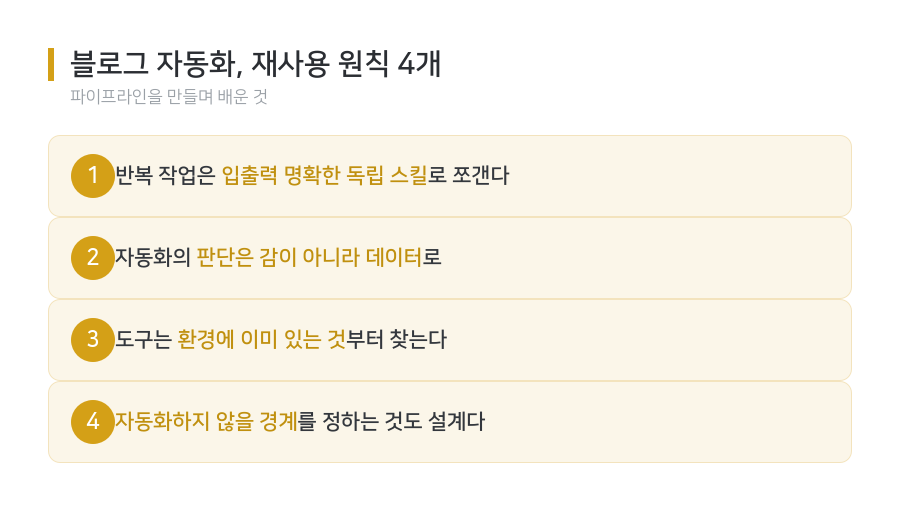
정리 — 재사용 가능한 원칙 4개
- 반복 작업은 입출력이 명확한 독립 스킬로 쪼갠다.
- 자동화의 판단은 데이터로 한다. 감은 자주 틀린다.
- 도구는 환경에 이미 있는 것부터 찾는다.
- 자동화하지 않을 경계를 정하는 것도 설계다.
자주 묻는 질문
Q. 왜 하나의 큰 프롬프트가 아니라 스킬 4개로 나눴나?
A. 유지보수와 합성 때문이다. 약한 단계만 독립적으로 교체할 수 있고, 각 스킬을 다른 파이프라인에서도 재사용할 수 있다.
Q. AI가 쓴 글이 구글에 걸리지 않나?
A. 구글은 “누가 썼나”가 아니라 “유용한가”를 본다. 짜깁기·양산은 걸리지만, 검색 의도를 충실히 답하고 원본 경험을 담으면 AI가 썼어도 노출된다.
Q. 이 구조를 다른 주제에도 쓸 수 있나?
A. 씨앗 분야만 바꾸면 된다. keyword-hunter의 입력을 “재테크”로 주든 “생활정보”로 주든 파이프라인은 동일하게 돈다.
다음 편에서는 이 블로그(codeparkway)를 실제로 배포한 과정 — CloudPanel과 워드프레스, SSL까지 — 을 정리해보려 한다.